
Le deep learning (apprentissage profond) est une branche du machine learning qui utilise des réseaux de neurones artificiels composés de plusieurs couches pour apprendre automatiquement des représentations complexes à partir de données brutes. C’est la technologie qui alimente aujourd’hui la reconnaissance d’images, la traduction automatique, les assistants vocaux, la conduite autonome, et l’ensemble de l’IA générative : ChatGPT, Midjourney, Stable Diffusion, DALL-E ou encore les outils de génération vidéo comme Sora.
Pour comprendre le deep learning, il faut d’abord comprendre ce qui le distingue du machine learning classique, puis saisir le fonctionnement des réseaux de neurones, les différentes architectures qui existent, et pourquoi cette technologie a explosé à partir de 2012 après des décennies de recherche.
Machine learning vs deep learning : quelle différence ?
Le machine learning classique et le deep learning partagent le même objectif : permettre à une machine d’apprendre à partir de données sans être explicitement programmée pour chaque tâche. La différence fondamentale réside dans la manière dont les caractéristiques des données sont extraites.
En machine learning traditionnel, un humain doit d’abord définir manuellement les caractéristiques pertinentes des données (on parle de feature engineering). Pour reconnaître un chat dans une image par exemple, un ingénieur devait concevoir des extracteurs de caractéristiques capables de détecter les contours, les textures, les formes. Un travail fastidieux, limité et spécifique à chaque problème.
Le deep learning élimine cette étape. Le réseau de neurones profond apprend lui-même à extraire les caractéristiques pertinentes directement à partir des données brutes, couche après couche, des motifs les plus simples (lignes, contours) aux concepts les plus abstraits (visage, objet, émotion). C’est cette capacité d’extraction automatique de caractéristiques hiérarchiques qui rend le deep learning si puissant pour le traitement d’images, de texte, de son et de vidéo.
En pratique, le deep learning surpasse le machine learning classique dès que le volume de données est suffisant et que les données sont non structurées. En revanche, sur des petits jeux de données tabulaires, les algorithmes classiques comme XGBoost ou Random Forest restent souvent plus performants et plus rapides à entraîner.
Comment fonctionne un réseau de neurones profond
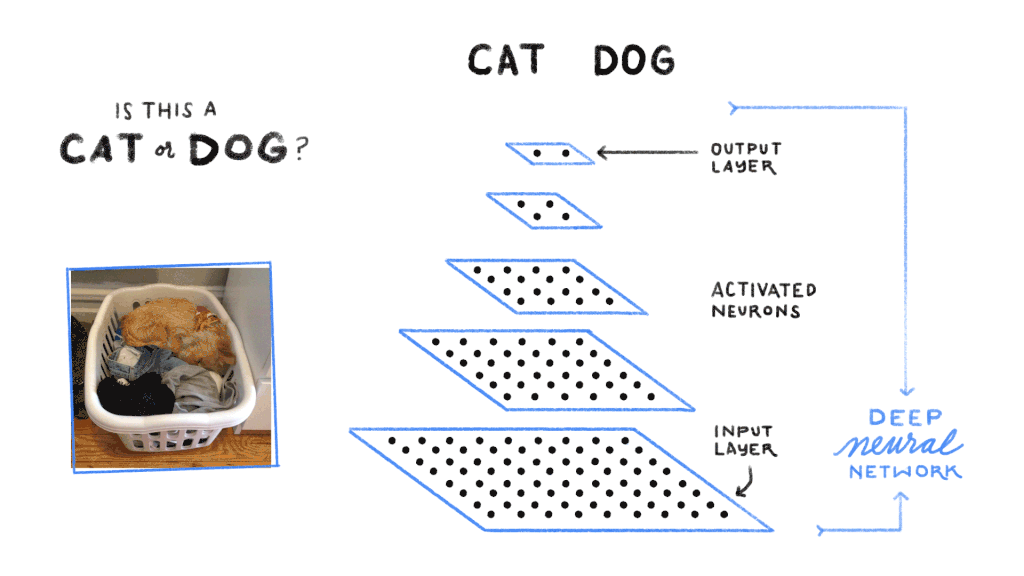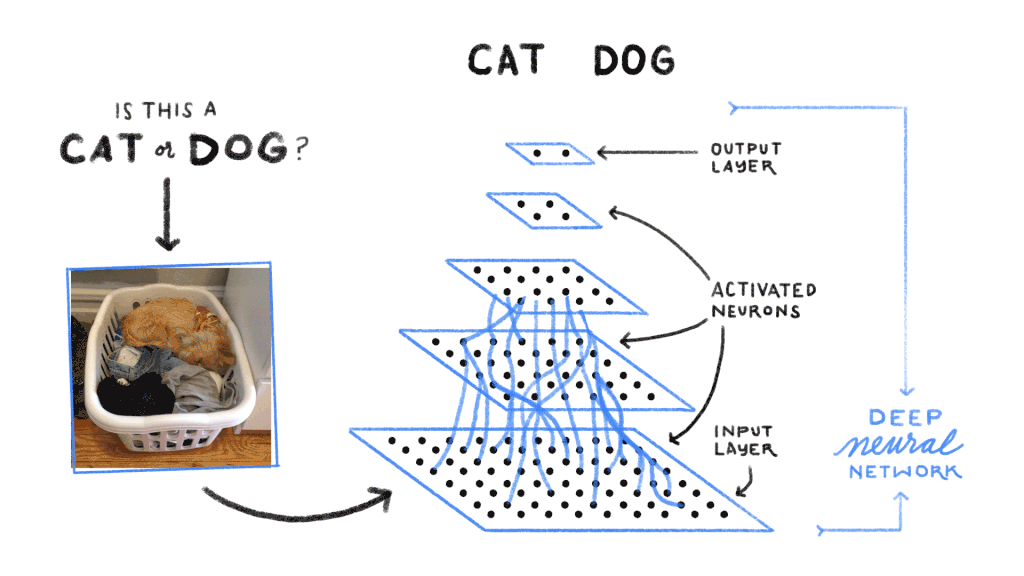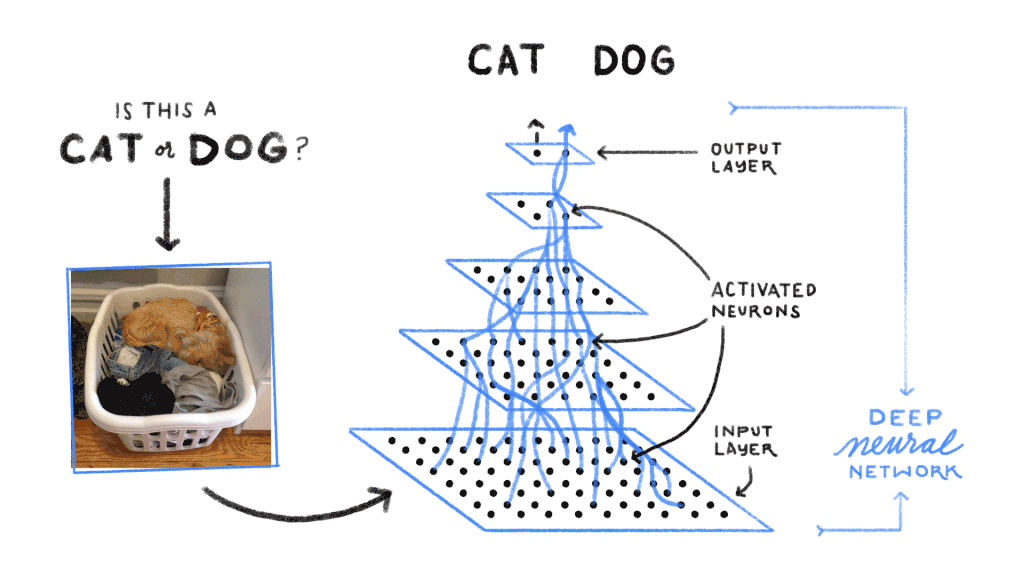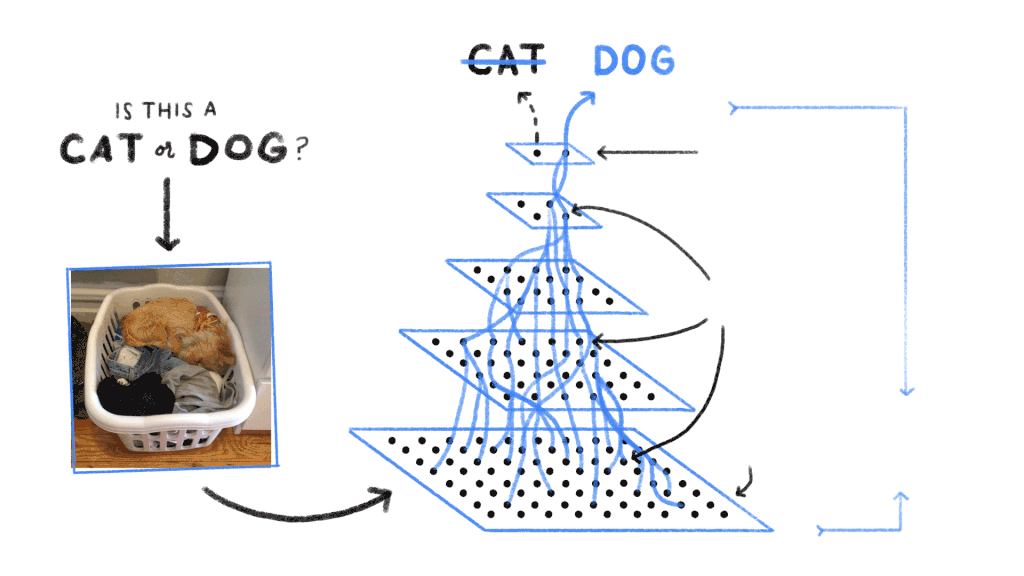
Le neurone artificiel
Le neurone artificiel est l’unité de base de tout réseau de neurones. Son fonctionnement s’inspire très librement du neurone biologique, sans en être une réplique fidèle. Concrètement, un neurone artificiel réalise trois opérations. Il reçoit un ensemble de valeurs d’entrée. Il multiplie chaque entrée par un poids (un nombre qui détermine l’importance de cette entrée), puis additionne le tout en ajoutant un biais. Il fait passer le résultat à travers une fonction d’activation (comme ReLU, sigmoïde ou tanh) qui introduit de la non-linéarité, sans cette non-linéarité, le réseau ne pourrait apprendre que des relations linéaires, ce qui serait extrêmement limitant.
Le concept du neurone artificiel remonte au perceptron de Frank Rosenblatt (1957), lui-même inspiré du modèle neuronal formel de Warren McCulloch et Walter Pitts (1943).
L’architecture en couches
Un réseau de neurones profond est organisé en couches successives. La couche d’entrée reçoit les données brutes (pixels d’une image, valeurs numériques d’un signal audio, encodage numérique d’un texte). Les couches cachées (hidden layers) transforment progressivement ces données en représentations de plus en plus abstraites. La couche de sortie produit le résultat final : une classe (chat, chien, voiture), une probabilité, une valeur numérique ou un texte généré.
La « profondeur » du réseau correspond au nombre de couches cachées. On parle généralement de deep learning à partir de 3 couches cachées, mais les architectures modernes en comptent des dizaines voire des centaines. ResNet (2015) a introduit des réseaux de 152 couches. Les modèles de type GPT comptent des dizaines de milliards de paramètres répartis sur des architectures de centaines de couches.
L’apprentissage : propagation avant et rétropropagation
L’entraînement d’un réseau de neurones se fait en deux phases qui se répètent des milliers ou des millions de fois.
La propagation avant (forward propagation) fait passer les données d’entrée à travers toutes les couches du réseau pour obtenir une prédiction. La rétropropagation (backpropagation) compare cette prédiction au résultat attendu, calcule l’erreur, puis ajuste les poids de chaque connexion en remontant du résultat vers l’entrée. L’objectif est de minimiser l’erreur globale du réseau par un algorithme d’optimisation (le plus courant étant la descente de gradient stochastique).
Ce processus est répété sur l’ensemble du jeu de données d’entraînement, souvent plusieurs dizaines d’itérations complètes (appelées époques). C’est cette boucle d’ajustement progressif qui constitue l’apprentissage du réseau.
Les grandes architectures du deep learning
Les réseaux de neurones convolutifs (CNN)
Les réseaux convolutifs (Convolutional Neural Networks) sont spécialisés dans le traitement d’images et de vidéos. Plutôt que de connecter chaque neurone à tous les pixels de l’image (ce qui serait ingérable pour une image de résolution courante), les CNN utilisent des filtres (ou noyaux de convolution) qui balayent l’image par petites zones pour détecter des motifs locaux.
Le fonctionnement est hiérarchique. Les premières couches détectent des motifs simples : contours, lignes, textures. Les couches intermédiaires combinent ces motifs pour reconnaître des formes plus complexes : yeux, roues, fenêtres. Les couches profondes identifient des concepts de haut niveau : un visage, une voiture, un bâtiment. Cette hiérarchie d’abstraction est ce qui rend les CNN si efficaces pour la vision par ordinateur.
Les architectures CNN marquantes incluent LeNet (Yann LeCun, 1998, reconnaissance de chiffres manuscrits), AlexNet (Alex Krizhevsky, 2012, victoire décisive sur ImageNet), GoogLeNet/Inception (2014, convolutions parallèles), VGGNet (2014, simplicité et profondeur), et ResNet (2015, connexions résiduelles permettant des réseaux de 152 couches).
Les CNN sont utilisés en reconnaissance faciale, en imagerie médicale (détection de tumeurs), en conduite autonome (interprétation des flux de caméras en temps réel), en contrôle qualité industriel et en VFX (rotoscopie automatique, upscaling).
Les réseaux de neurones récurrents (RNN)
Les réseaux récurrents (Recurrent Neural Networks) sont conçus pour traiter des données séquentielles — du texte, du son, des séries temporelles — où l’ordre des éléments compte. Contrairement aux CNN qui traitent chaque entrée indépendamment, les RNN possèdent une « mémoire interne » : la sortie d’une étape de la séquence est réinjectée comme entrée de l’étape suivante. Le réseau conserve ainsi un état caché (hidden state) qui encode le contexte des éléments précédents.
Le problème principal des RNN classiques est la disparition du gradient : sur les longues séquences, le signal d’erreur s’affaiblit au point de rendre l’apprentissage impossible pour les dépendances lointaines. Les architectures LSTM (Long Short-Term Memory, Hochreiter et Schmidhuber, 1997) et GRU (Gated Recurrent Unit) résolvent ce problème grâce à des mécanismes de portes (gates) qui décident quelles informations conserver ou oublier.
Les RNN et LSTM ont longtemps dominé le traitement du langage naturel, la reconnaissance vocale, la traduction automatique et la prédiction de séries temporelles, avant d’être largement remplacés par les Transformers à partir de 2017.
Les Transformers
L’architecture Transformer, introduite par Google Brain en 2017 dans l’article fondateur « Attention Is All You Need » (Vaswani et al.), est la révolution la plus importante du deep learning depuis AlexNet. Les Transformers remplacent la récurrence des RNN par un mécanisme d’attention (self-attention) qui permet au modèle de pondérer l’importance de chaque élément de la séquence par rapport à tous les autres, simultanément et en parallèle.
Cette parallélisation est un avantage considérable : là où les RNN traitent les séquences mot par mot (ce qui est lent), les Transformers traitent toute la séquence en une seule passe, ce qui exploite pleinement la puissance des GPU modernes.
Les Transformers sont la base de pratiquement tous les modèles de langage modernes. BERT (Google, 2018) utilise l’architecture encoder du Transformer pour la compréhension du langage (classification, extraction d’entités, question-réponse). GPT (OpenAI, 2018-2024) utilise l’architecture decoder pour la génération de texte, c’est la technologie derrière ChatGPT. Les Vision Transformers (ViT, 2020) appliquent le même mécanisme d’attention aux images, démontrant que les Transformers peuvent rivaliser avec les CNN sur les tâches de vision par ordinateur.
Les réseaux antagonistes génératifs (GAN)
Les GAN (Generative Adversarial Networks), inventés par Ian Goodfellow en 2014, fonctionnent sur un principe élégant : deux réseaux s’affrontent. Le générateur crée de fausses données (images, sons) en essayant de tromper le discriminateur. Le discriminateur tente de distinguer les vraies données des fausses. Les deux réseaux s’améliorent mutuellement dans cette compétition, jusqu’à ce que le générateur produise des résultats indiscernables des données réelles.
Les GAN ont été à la pointe de la génération d’images photoréalistes (StyleGAN de NVIDIA, deepfakes, super-résolution) avant d’être progressivement complétés par les modèles de diffusion (Stable Diffusion, DALL-E, Midjourney) qui offrent un entraînement plus stable et des résultats plus contrôlables.
Les modèles de diffusion
Les modèles de diffusion sont l’architecture derrière la révolution de l’IA générative d’images depuis 2022. Leur principe est contre-intuitif : le modèle apprend à ajouter du bruit à une image progressivement jusqu’à obtenir du bruit pur, puis apprend le processus inverse, partir du bruit pur et le « débruiter » pas à pas pour reconstruire une image cohérente. En conditionnant ce processus de débruitage par un texte (via un encodeur comme CLIP), le modèle peut générer des images correspondant à une description textuelle.
Stable Diffusion (Stability AI), DALL-E (OpenAI) et Midjourney utilisent tous des architectures de diffusion, souvent combinées avec des Transformers pour l’encodage du texte.
Comparatif des architectures
| Architecture | Spécialité | Fonctionnement clé | Exemples d'application |
|---|---|---|---|
| CNN (Convolutif) | Images, vidéos | Filtres de convolution détectant des motifs hiérarchiques | Reconnaissance faciale, imagerie médicale, conduite autonome |
| RNN / LSTM | Séquences (texte, son, séries temporelles) | Mémoire interne, traitement séquentiel | Traduction, reconnaissance vocale, prédiction financière |
| Transformer | Langage, vision, multimodal | Mécanisme d’attention, traitement parallèle | ChatGPT, BERT, GPT-4, Vision Transformer |
| GAN | Génération d’images, vidéos | Compétition générateur vs discriminateur | StyleGAN, deepfakes, super-résolution |
| Diffusion | Génération d’images et vidéos | Débruitage progressif conditionné par du texte | Stable Diffusion, DALL-E, Midjourney, Sora |
Pourquoi le deep learning a explosé en 2012
Le concept de réseau de neurones existe depuis les années 1940, et la rétropropagation est connue depuis les années 1980. Pourquoi le deep learning n’a-t-il décollé qu’en 2012 ?
Trois facteurs ont convergé simultanément.
Les données massives. L’essor d’Internet a rendu disponibles des jeux de données gigantesques. ImageNet, créé en 2009 par l’équipe de Fei-Fei Li à Stanford, contient plus de 14 millions d’images classifiées en 20 000 catégories. C’est ce dataset qui a permis d’entraîner des réseaux profonds de manière efficace. Sans données massives, les réseaux de neurones profonds ne peuvent pas apprendre. Ils ont besoin de millions d’exemples pour ajuster leurs milliards de paramètres.
La puissance de calcul GPU. Les cartes graphiques NVIDIA, conçues initialement pour le jeu vidéo et le rendu 3D, se sont révélées parfaitement adaptées à l’entraînement de réseaux de neurones grâce à leur architecture massivement parallèle. Un GPU peut effectuer des milliers d’opérations matricielles simultanément, là où un CPU les traite séquentiellement. L’entraînement d’AlexNet sur GPU a été 10 à 20 fois plus rapide que sur CPU, rendant viable l’entraînement de réseaux profonds sur de grands datasets pour la première fois.
L’article AlexNet. En 2012, Alex Krizhevsky, Ilya Sutskever et Geoffrey Hinton publient AlexNet, un réseau convolutif profond entraîné sur ImageNet avec des GPU NVIDIA. Le résultat est spectaculaire : AlexNet remporte le concours ImageNet Large Scale Visual Recognition Challenge (ILSVRC) avec un taux d’erreur de 15,3%, écrasant le précédent record de 26% obtenu par des méthodes traditionnelles. Cette amélioration de 10 points en une seule année a convaincu la communauté scientifique que le deep learning fonctionnait réellement à grande échelle, déclenchant une vague d’investissements et de recherches sans précédent.
Histoire du deep learning : les dates clés

1943 — Warren McCulloch et Walter Pitts publient le premier modèle mathématique du neurone artificiel.
1957 — Frank Rosenblatt construit le perceptron, le premier réseau de neurones capable d’apprentissage.
1969 — Marvin Minsky et Seymour Papert publient « Perceptrons », démontrant les limites du perceptron simple, déclenchant le premier « hiver de l’IA » et un déclin du financement de la recherche sur les réseaux de neurones.
1986 — David Rumelhart, Geoffrey Hinton et Ronald Williams formalisent la rétropropagation du gradient, rendant possible l’entraînement de réseaux multicouches.
1989 — Yann LeCun développe LeNet, le premier réseau convolutif (CNN), appliqué à la reconnaissance de chiffres manuscrits pour les chèques bancaires.
1997 — Sepp Hochreiter et Jürgen Schmidhuber inventent le LSTM, résolvant le problème de la disparition du gradient dans les RNN.
2006 — Geoffrey Hinton propose les Deep Belief Networks et popularise le terme « deep learning », relançant l’intérêt pour les réseaux profonds après un second hiver de l’IA.
2012 — AlexNet remporte ImageNet et déclenche la révolution du deep learning. Google dévoile Google Brain, capable de reconnaître des chats dans des vidéos YouTube sans supervision.
2014 — Ian Goodfellow invente les GAN (Generative Adversarial Networks). Facebook développe DeepFace, un système de reconnaissance faciale atteignant une précision de 97,35%.
2015 — ResNet (Microsoft Research) introduit les connexions résiduelles et atteint 152 couches. AlphaGo (DeepMind) bat le champion européen de Go.
2016 — AlphaGo bat le champion du monde Lee Sedol au Go, un événement considéré comme impossible par la communauté scientifique quelques années plus tôt.
2017 — Google Brain publie « Attention Is All You Need », introduisant l’architecture Transformer qui va révolutionner le traitement du langage naturel et bien au-delà.
2018 — Google lance BERT (encoder Transformer) pour la compréhension du langage. OpenAI lance GPT-1 (decoder Transformer) pour la génération de texte. Les deux modèles démontrent que les Transformers pré-entraînés sur de grands corpus de texte peuvent être finement ajustés pour des tâches spécifiques avec très peu de données supplémentaires.
2020 — OpenAI lance GPT-3 avec 175 milliards de paramètres, le plus grand modèle de langage de son époque. AlphaFold (DeepMind) résout le problème du repliement des protéines, un défi vieux de 50 ans en biologie.
2021 — OpenAI lance DALL-E, le premier système de génération d’images à partir de texte utilisant un Transformer.
2022 — Stable Diffusion, Midjourney et DALL-E 2 lancent la révolution de l’IA générative d’images. En novembre, OpenAI lance ChatGPT, qui atteint 100 millions d’utilisateurs en deux mois, le produit à la croissance la plus rapide de l’histoire.
2023 — GPT-4 (OpenAI) introduit la multimodalité (texte + images). Meta lance LLaMA, rendant les LLM open-weight accessibles à la communauté. Google lance Gemini.
2024 — Les modèles de raisonnement émergent avec OpenAI o1. Les modèles multimodaux se généralisent (texte, image, audio, vidéo). DeepSeek-R1 démontre qu’un modèle compétitif peut être entraîné à une fraction du coût des modèles occidentaux.
2025-2026 — Les modèles deviennent plus efficaces (small language models), l’IA on-device progresse, et les architectures alternatives aux Transformers (comme Mamba, basée sur les state space models) émergent comme compétiteurs sérieux.
Les applications concrètes du deep learning
Vision par ordinateur
La reconnaissance d’images est le domaine fondateur du deep learning moderne. Les CNN sont utilisés pour la reconnaissance faciale (Face ID d’Apple), la classification d’images (Google Photos), la détection d’objets en temps réel (conduite autonome), le contrôle qualité industriel (détection de défauts sur des pièces de production), et l’imagerie médicale (détection de tumeurs, analyse de radiographies, diagnostic de mélanomes avec une précision proche de celle d’un dermatologue spécialiste).
Traitement du langage naturel (NLP)
Les Transformers ont transformé le NLP. Les chatbots (ChatGPT, Claude, Gemini) génèrent du texte cohérent et contextuellement pertinent. La traduction automatique (DeepL, Google Translate) atteint une qualité quasi humaine. L’analyse de sentiment, l’extraction d’entités nommées, le résumé automatique et la génération de code sont désormais des tâches courantes pour les modèles de deep learning.
Génération d’images et de vidéos
Les modèles de diffusion (Stable Diffusion, DALL-E, Midjourney) et les GAN (StyleGAN) permettent de générer des images photoréalistes ou stylisées à partir de descriptions textuelles. Les outils de génération vidéo (Sora d’OpenAI, Runway Gen-3, Kling) produisent des clips vidéo à partir de texte. Ces technologies sont utilisées en publicité, en motion design, en concept art et en production de contenu.
Reconnaissance et synthèse vocale
La reconnaissance vocale (Siri, Alexa, Google Assistant, Whisper d’OpenAI) repose sur des modèles deep learning entraînés sur des milliers d’heures d’audio. La synthèse vocale (text-to-speech) produit des voix artificielles de plus en plus naturelles, utilisées dans les podcasts, le doublage et les assistants virtuels. ElevenLabs propose du clonage vocal de haute qualité basé sur le deep learning.
Sciences et recherche
AlphaFold (DeepMind) a prédit la structure 3D de plus de 200 millions de protéines, accélérant la recherche en biologie et en pharmacologie. Le deep learning est utilisé en physique des particules (analyse des données du CERN), en astronomie (détection d’exoplanètes), en climatologie (prédiction météorologique) et en chimie (découverte de nouveaux matériaux et de médicaments).
Conduite autonome
Les véhicules autonomes (Tesla, Waymo, Cruise) combinent des CNN pour l’interprétation des caméras, des Transformers pour la planification de trajectoire, et de l’apprentissage par renforcement pour la prise de décision. Le deep learning traite en temps réel les flux de dizaines de caméras, de capteurs LiDAR et de radars pour construire une représentation 3D de l’environnement.
Création 3D et VFX
Le deep learning transforme les pipelines de modélisation 3D et de VFX. Le denoising par IA (NVIDIA OptiX, Arnold OIDN) réduit les temps de rendu par un facteur 2 à 5. Les NeRF et le Gaussian Splatting permettent de reconstruire des scènes 3D à partir de photos. La rotoscopie automatique, le suivi de mouvement et la génération de textures procédurales utilisent tous des réseaux de neurones profonds.
Les frameworks et outils du deep learning
| Framework | Éditeur | Licence | Spécificité |
|---|---|---|---|
| PyTorch | Meta (Facebook AI Research) | Open source | Favori des chercheurs, calcul dynamique, écosystème Hugging Face |
| TensorFlow | Open source | Standard en production, écosystème complet (TFLite, TF.js, TF Serving) | |
| Keras | François Chollet (Google) | Open source | API haut niveau, intégrée à TensorFlow, idéale pour le prototypage rapide |
| JAX | Google DeepMind | Open source | Calcul haute performance, différentiation automatique, populaire en recherche |
| Hugging Face Transformers | Hugging Face | Open source | Bibliothèque de modèles pré-entraînés (LLM, vision, audio), standard pour le NLP |
PyTorch domine la recherche académique grâce à son graphe de calcul dynamique qui facilite le débogage et l’expérimentation. TensorFlow avec Keras reste le choix privilégié pour le déploiement en production grâce à son écosystème complet (mobile, web, serveur). Hugging Face est devenu incontournable comme hub de modèles pré-entraînés : des milliers de modèles (BERT, GPT, Stable Diffusion, Whisper) sont disponibles en téléchargement et utilisables en quelques lignes de code.
Le matériel : pourquoi les GPU sont indispensables
L’entraînement d’un réseau de neurones profond consiste essentiellement en des multiplications de matrices, des opérations que les GPU, avec leurs milliers de cœurs de calcul parallèles, exécutent bien plus rapidement que les CPU. Un GPU NVIDIA de génération récente peut accélérer l’entraînement d’un facteur 10 à 100 par rapport à un CPU seul.
Les cartes NVIDIA dominent le marché du deep learning grâce à leur écosystème logiciel CUDA et à leurs bibliothèques optimisées (cuDNN). Les GPU de la série A100 et H100 sont les standards des data centers d’entraînement. Les cartes grand public (RTX 4090, RTX 5090) permettent l’entraînement de modèles de taille modérée et l’inférence locale.
Google a développé ses propres accélérateurs, les TPU (Tensor Processing Units), optimisés spécifiquement pour les opérations de deep learning. AWS propose les puces Trainium et Inferentia. Ces accélérateurs spécialisés réduisent les temps d’entraînement et les coûts énergétiques par rapport aux GPU généralistes.
L’entraînement des modèles les plus grands (GPT-4, Gemini, Claude) nécessite des clusters de milliers de GPU ou de TPU, répartis dans des data centers consommant des dizaines de mégawatts d’électricité. Le coût d’entraînement d’un modèle comme GPT-4 est estimé à plus de 100 millions de dollars.
Les limites et défis du deep learning
Le besoin en données. Les modèles de deep learning nécessitent des volumes considérables de données pour être performants. Dans les domaines où les données étiquetées sont rares ou coûteuses à produire (imagerie médicale, langues minoritaires), le deep learning reste difficile à appliquer. Les techniques de transfer learning (réutilisation de modèles pré-entraînés) et de few-shot learning atténuent ce problème mais ne l’éliminent pas.
Le coût énergétique et environnemental. L’entraînement des grands modèles consomme des quantités massives d’énergie. Des chercheurs estiment que l’entraînement de GPT-3 a émis environ 500 tonnes de CO₂. La course aux modèles toujours plus grands pose des questions environnementales que la communauté commence à prendre en compte, avec un intérêt croissant pour les modèles plus petits et plus efficaces (small language models, quantification, distillation).
L’interprétabilité. Les réseaux de neurones profonds sont souvent décrits comme des « boîtes noires » : ils produisent des résultats corrects mais il est difficile de comprendre pourquoi. Dans des domaines critiques comme la médecine, la justice ou la finance, ce manque de transparence pose des problèmes d’acceptation et de réglementation. Le champ de recherche en IA explicable (XAI, Explainable AI) travaille à rendre les décisions des modèles plus compréhensibles.
Les biais. Les modèles de deep learning reproduisent et peuvent amplifier les biais présents dans leurs données d’entraînement. Si un modèle est entraîné sur des données historiques biaisées (par exemple, des données de recrutement défavorisant certains groupes), ses prédictions seront tout aussi biaisées. La détection et la correction de ces biais sont des enjeux majeurs de la recherche actuelle.
Les hallucinations. Les modèles de langage (LLM) ont tendance à générer des informations fausses mais formulées avec assurance, un phénomène appelé « hallucination ». Ce problème, inhérent à l’architecture même des modèles génératifs (qui prédisent le mot le plus probable et non le mot le plus vrai), reste l’un des défis les plus importants de l’IA générative.
Tendances 2025-2026
Modèles plus petits et plus efficaces
La course aux modèles géants montre ses limites en termes de coût et d’accessibilité. Les small language models (SLM) comme Phi (Microsoft), Gemma (Google) et les versions compactes de LLaMA (Meta) démontrent que des modèles plus petits, entraînés sur des données de meilleure qualité, peuvent rivaliser avec des modèles beaucoup plus grands sur des tâches spécifiques. La quantification (réduction de la précision des poids de 32 bits à 4 ou 8 bits) et la distillation (entraîner un petit modèle à imiter un grand modèle) permettent de déployer des modèles performants sur des appareils mobiles ou des serveurs modestes.
IA on-device et edge computing
Le deep learning migre des data centers vers les appareils. Les puces des smartphones (Apple Neural Engine, Qualcomm Hexagon) et les GPU embarqués (NVIDIA Jetson) permettent d’exécuter des modèles de deep learning localement, sans connexion Internet. Cette tendance est poussée par les exigences de confidentialité, de latence et de disponibilité.
Modèles multimodaux
Les modèles récents ne se limitent plus à un seul type de données. GPT-4o, Gemini et Claude traitent simultanément du texte, des images, de l’audio et de la vidéo. Cette convergence vers des modèles « universels » capables de comprendre et de générer n’importe quel type de contenu est l’une des tendances les plus marquantes de la recherche actuelle.
Architectures alternatives aux Transformers
L’architecture Transformer domine depuis 2017, mais des alternatives émergent. Mamba (modèle basé sur les state space models) offre des performances comparables aux Transformers pour les LLM avec une consommation mémoire nettement inférieure. RWKV combine des éléments de RNN et de Transformers. Ces architectures pourraient s’imposer pour les modèles nécessitant de très longues fenêtres de contexte ou un déploiement sur du matériel contraint.
Agents IA et raisonnement
Les modèles de deep learning évoluent au-delà de la simple génération de contenu vers des systèmes capables de raisonnement et d’action autonome. Les agents IA (comme ceux construits sur GPT-4, Claude ou Gemini) peuvent planifier des tâches, utiliser des outils, naviguer sur le web et exécuter des actions dans le monde réel. Les modèles de raisonnement (OpenAI o1, DeepSeek-R1) génèrent des chaînes de pensée explicites avant de produire une réponse, améliorant significativement leurs performances sur les tâches logiques et mathématiques.
Les pionniers du deep learning
Trois chercheurs sont souvent désignés comme les « pères du deep learning » et ont reçu le prix Turing 2018 (considéré comme le Nobel de l’informatique) pour leurs travaux fondateurs.
Geoffrey Hinton (Université de Toronto, Google Brain) a travaillé sur la rétropropagation dans les années 1980, les Deep Belief Networks dans les années 2000, et a co-supervisé AlexNet en 2012. Il a reçu le prix Nobel de physique 2024 pour ses travaux sur les réseaux de neurones.
Yann LeCun (Meta AI, NYU) est l’inventeur des réseaux convolutifs (CNN) avec LeNet. Il dirige la recherche en IA chez Meta et est un défenseur des approches open-source en IA.
Yoshua Bengio (Université de Montréal, Mila) a contribué aux fondations théoriques du deep learning, notamment sur les modèles de langage neuronaux et les GAN. Il est un ardent défenseur de la recherche sur la sécurité de l’IA.